Vroeger op de middelbare school heb ik meer de Beta richting gekozen dus Biologie heb ik niet echt veel gehad. Maar nu met een spoedcursus Biologie bezig want het onderwerp van een van onze nieuwe start-ups is het vakgebied “Computational Biology”. Dit vakgebied komt in een stroomversnelling door nieuwe technologische doorbraken in de afgelopen 6 maanden. Dit doen we gelukkig samen met zeer ervaren chemie en biologie experts.
Eiwitten zijn zo ongeveer de belangrijkste building blocks in elk levend wezen. De chemische industrie is gebaseerd op eiwit gebaseerde processen. Het gros van de pharma industrie is gebaseerd op eiwitten (denk bijvoorbeeld aan de Covid vaccins).
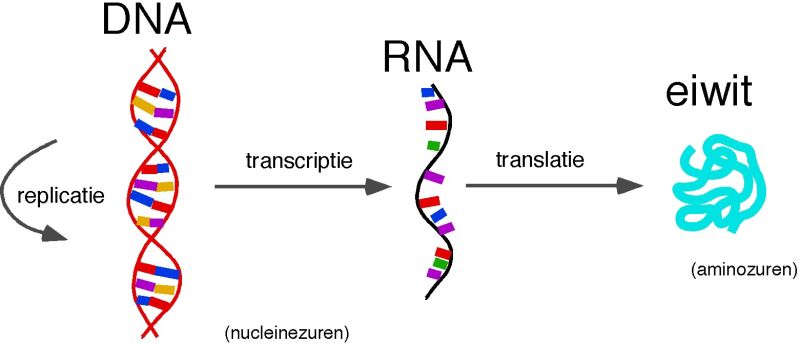
In het DNA ligt vast hoe ons eigen lichaam eiwitten produceert in cellen. DNA wordt omgezet in RNA (een soort mal) en met deze mal worden de eiwitten gemaakt vanuit sequenties van de 20 basis aminozuren. Vanuit die 20 aminozuren worden zo een enorm groot aantal eiwitten gemaakt. De volgorde van die aminozuur sequentie bepaalt eigenlijk 1-op-1 het eiwit en de 3D structuur daarvan. En als je die 3D structuur betrouwbaar hebt, gaat er vervolgens een wereld van mogelijkheden open.
Die 3D structuur voorspellen wordt al meer dan 30 jaar geprobeerd maar zelfs de beste modellen kwamen niet hoger dan 60% betrouwbaarheid (terwijl in het lab experimenteel bepaalde 3D structuren een betrouwbaarheid van 90% hebben, dat is echter een zeer duur proces). De nieuwste A.I. modellen halen inmiddels echter een betrouwbaarheid van 90%.
Dat maakt het potentieel mogelijk om allerlei zaken in een supercomputer uit te rekenen:
– het optimaliseren van chemische fabrieken door het uitrekenen van de optimale enzymreactie
– op basis van de Covid spike proteins uitrekenen welke bestaande geneesmiddelen of planten extracten het beste zouden werken
– op basis van een DNA test een Digital Twin van het menselijk lichaam bouwen (op eiwit niveau) zodat je (1) personalized medicines kunt maken, (2) kunt testen hoe bepaalde medicijnen zullen aanslaan bij een specifiek individu en (3) wat je zou moeten eten om gezonder te worden
– het geautomatiseerd vinden van ziekte receptoren in het menselijk lichaam, bijbehorende actieve ingredienten en de bijhorende ziekten (enorm disruptive voor biotech industrie)
– Als we een database opbouwen van 100K DNA samples, zouden we nieuwe geneesmiddelen (phase 3 trials) al in de computer op 100K mensen kunnen testen.
We hebben reeds een launching customer/aandeelhouder in de chemische industrie dus daar gaan we starten. In chemische fabrieken zijn de gebruikte eiwitten relatief simpel (vergeleken met pharma) en is omgeving meer gecontroleerd. Daarnaast verzamelt onze launching customer nu datasets die reeds gevalideerd zijn in een Wet Lab. Zodat we straks het gehele A.I. model ook goed kunnen testen en valideren.
Ook Google Deepmind heeft dit vakgebied ontdekt en heeft vorige week aangekondigd er een apart bedrijf voor op te zetten.
#genzai #ai #biology

